機器學習中的目標編碼
目標是算資料的平均值
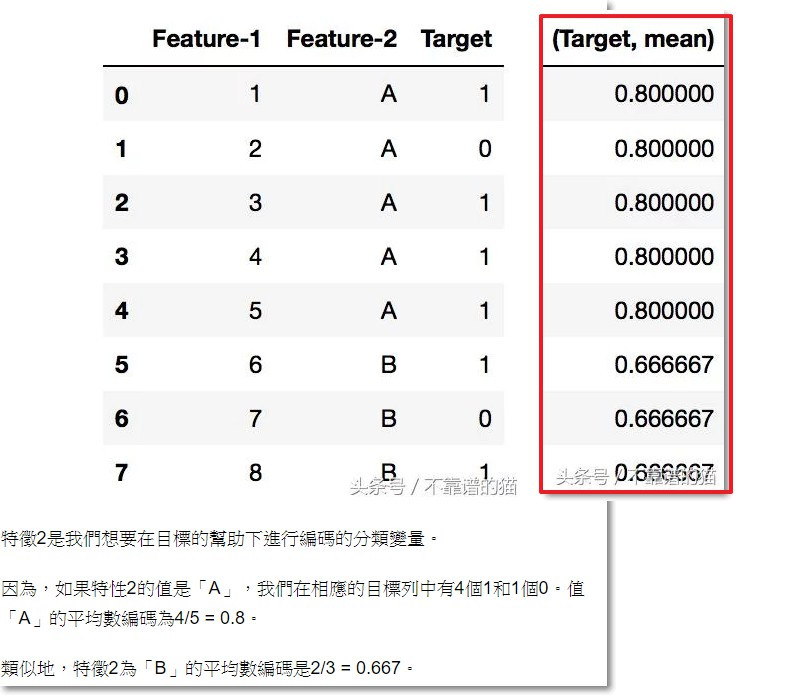
同學原本最初的想法是用sapply寫,但我看了下需求,我寫下了group_by() %>% summarise(mean()), 再用一個left_join就可以達到目標了。先分類,然後根據每個分類的結果做平均。有點像是excel樞紐分析表(對所以我也下意識地寫出了table())
可是這個操作不會只執行一次,你有個23個變數要做這樣的目標編碼,就我對group_by()的認知,我要寫23遍一模一樣的東西。
iris_test = iris
iris_test %>% group_by(Species) %>% summarise(mean = mean(Sepal.Length))

後來我找到有點久沒用的aggregate()函數
記得再寫數字的時候要用[[5]] 兩個中框號,因為他需要的是list ,沒框號的話長度會是1,便無法執行。
dat = list()
for(i in 1 :ncol(fraud_train)-1){
dat[[i]] = data.frame(aggregate(fraud_train$fraud_ind, by=list(fraud_train[[i]]), FUN=mean))
colnames(dat[[i]]) = c(title_tab[i],title_target[i])
}


